 热点资讯
热点资讯
宝可梦GO偷家李飞飞空间智能?全球最强3D地图诞生
编辑:HYZ
【新智元导读】5年,5000万个神经网络,这个世界从未被扫描过的角落,我们都能看到了。宝可梦GO团队,竟然抢先实现了李飞飞的「空间智能」?而「Pokémon Go」的玩家可能没想到,自己居然在训练着一个巨大的AI模型。
李飞飞提出的「空间智能」概念,被宝可梦GO团队抢先实现了?
最近,宝可梦GO团队宣布,构建出了一个大规模地理空间模型LGM,让我们距离空间智能更近了一步。
而这一成果也意味着,人类在空间计算和AR眼镜领域,即将进入崭新的时代。
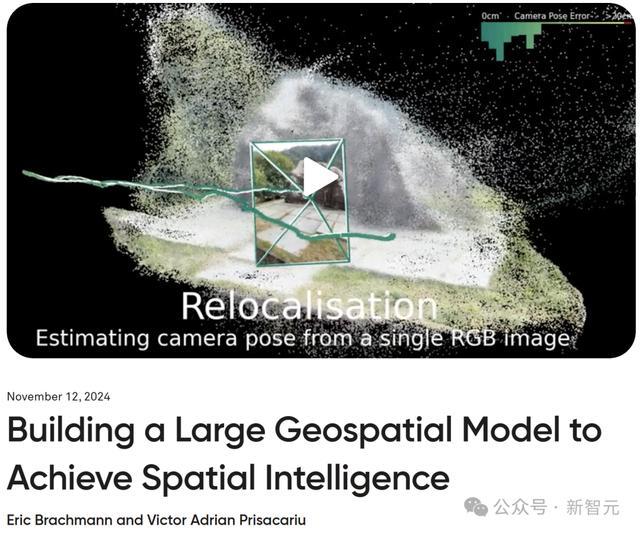
作为Niantic视觉定位系统(VPS)的一部分,团队训练了超过5000万个神经网络,参数规模超过150万亿。
我们可以把LGM想象成一张为计算机准备的超级智能地图,不过,它却能以与人类类似的方式理解空间。
凭借这种对世界的强大3D理解能力,LGM能够非常智能地「填补空白」,甚至包括那些地球上人类尚未全面扫描的领域!

可以说是,让AI终于长出了眼睛
从此,LGM将使计算机不仅能感知和理解空间,还能以新的方式与之互动,这就意味着AR眼镜和机器人、内容创建、自主系统等领域将迎来全新的突破。
随着我们从手机转向与现实世界相连的可穿戴技术,空间智能,将成为未来世界的操作系统!

全球数百万个场景,通过AI相连
这个大规模地理空间模型的概念,是利用大规模机器学习理解场景,然后它就会与全球数百万个其他场景相连。
你是否曾有这样的感觉?
看到一种熟悉的建筑,比如教堂、雕像或城镇广场,我们很容易想象它从其他角度看起来是什么样子,即使这些角度我们从未见过。

这,就是我们人类独有的「空间理解」功能,它意味着,我们可以根据以前遇到的无数相似场景来填补这些细节。
但这种能力对于机器来说,却是难如登天。
即使当今最先进的AI模型,也难以推断出场景中缺失的部分、将其可视化,或者想象出一个地方从全新的角度看起来是什么样子。
如今,LGM打破了AI的这种限制!
这套由宝可梦GO团队训练出的神经网络,可以在超过100万个地点进行操作。
每个本地网络,都会为全球大模型做出贡献,实现对地理位置的贡献理解,包括那些尚未扫描的地方。

什么是大规模地理空间模型
我们都知道,LLM是通过在互联网规模的文本集合上进行训练后,从而理解和生成书面语言。
这种方式,挑战了我们对「智能」的理解。
同样,大规模地理空间模型也是以一种同样先进的方式,帮助计算机感知、理解物理世界,为之导航。
跟LLM类似,它同样是通过大量原始数据构建的——
数十亿张全球各地的图像,全部锚定在地球上的精确位置,被提炼成一个大模型,让计算机能够基于位置去理解空间、结构和物理交互。
从基于文本的模型向基于3D数据的模型的转变,也揭示出近年来AI发展的一条轨迹:从理解和生成语言,到解释和创建静态和动态图像(2D视觉模型),再到对物体的3D外观进行建模(3D视觉模型)。
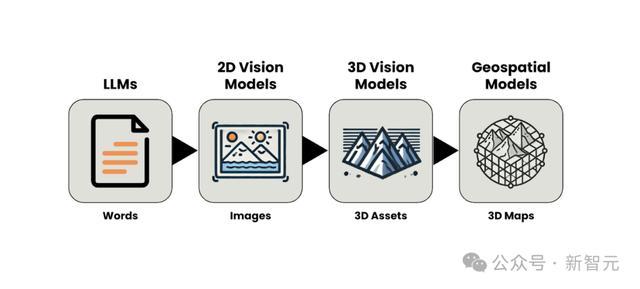
而现在,地理空间模型甚至比3D视觉模型更进一步,因为它们捕捉的是根植于特定地理位置、并且具有度量特性的3D实体。
与典型的生成式3D模型不同,大规模地理空间模型绑定到了度量空间,因而能够以尺度度量单位进行精确的估算,而前者生成的,只是未缩放的资产。
因此,这些实体代表的是下一代地图,而非任意的3D资产。
虽然3D视觉模型也能创建和理解3D场景,但地理空间模型却理解该场景如何与全球数百万其他场景在地理上相关联。
它实现了一种地理空间智能,让模型从其先前的观察中学习,然后还能将知识转移到新的位置,即使这些位置只是被部分观察到的。

现在,带有3D图形的AR眼镜距离大规模市场化还有几年时间,但地理空间模型已经有机会与纯音频或2D显示的眼镜集成了!
想象一下,这些模型可以引导我们穿越世界,回答问题,提供个性化推荐,提供导航,甚至增强我们与现实世界的互动。
而且,它还可以集成LLM,让理解和空间融合在一起,让人们能更加了解自己周边的环境和社区,并且与之互动。
这种地理空间智能还能生成和操纵世界的3D表示,构建下一代AR体验。
除了游戏之外,在空间规划和设计、物流、观众互动和远程协作上,大规模地理空间模型都将具有无限的潜力。
5000万个神经网络,详细了解整个世界
为了构建视觉定位系统VPS,Niantic团队已经花费了五年。
这个系统仅利用手机上的单张图像,就能让用户在团队的游戏和Scaniverse中有趣的地点构建3D地图,从而确定其位置和方向。
有了VPS,用户就可以以厘米级的精度,在世界中定位自己!
这就意味着,他们可以精确而真实地看到放置到物理环境中的数字内容。
这些内容是持久的,即使你离开后,它们仍然会留在原地,还能与他人共享。

比如,团队最近在Pokémon GO中推出了一项名为Pokémon Playgrounds的实验功能,让用户在特定位置上放置宝可梦,将它们留在原地,供其他人查看和互动
所以,VPS是怎样创建出对世界如此高度详细的理解呢?
原来,Niantic的VPS都是通过用户扫描构建的。
这些用户会通过不同的视角拍摄,并且还会在一天中的不同时间,以及多年来的多次拍摄,同时附有定位信息,从而创建出了对世界高度详细的理解。
这些数据是独一无二的,因为它们是从行人视角获取,包括了汽车无法到达的地方。
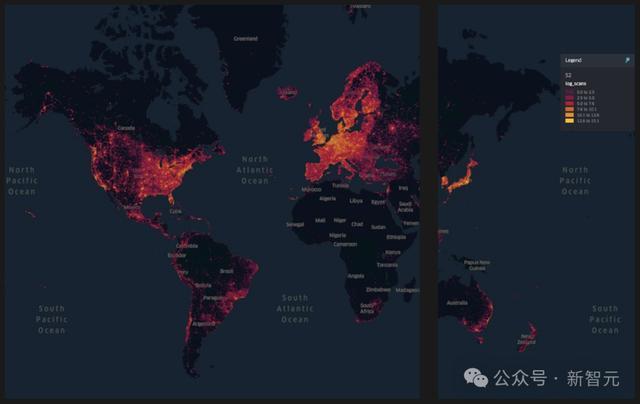
如今团队已经在全球范围内拥有1000万个扫描地点,其中超过100万个已激活,可供VPS使用了。
而且,团队每周还在接收约100万次新的扫描,每次扫描都包含数百张独立的图像。
作为VPS的一部分,团队使用运动结构技术构建经典的3D视觉地图,同时也为每个地点构建了一种新型的神经地图。
这些神经模型基于ACE(2023)和ACE Zero(2024)这两篇论文,不再使用经典的3D数据结构来表示位置,而是将它们隐式编码在神经网络的可学习参数中。
这些网络可以快速地将数千张地图图像压缩成精简的神经表示。
给定一张新的查询图像,它们以厘米级的精度,对这个位置进行精确定位。
Niantic训练的超过5000万个神经网络中,多个网络都可以为单个位置做贡献。
所有这些网络结合起来后,总共包含了超过150万亿个通过机器学习优化的参数。
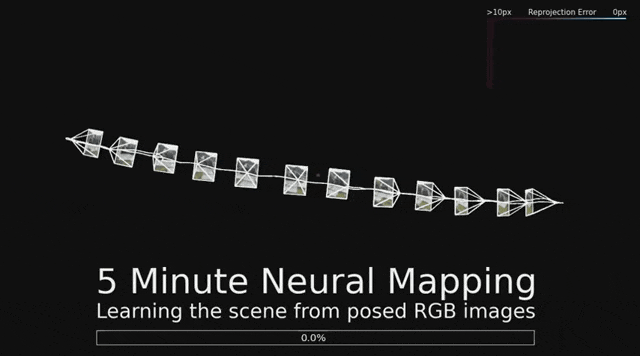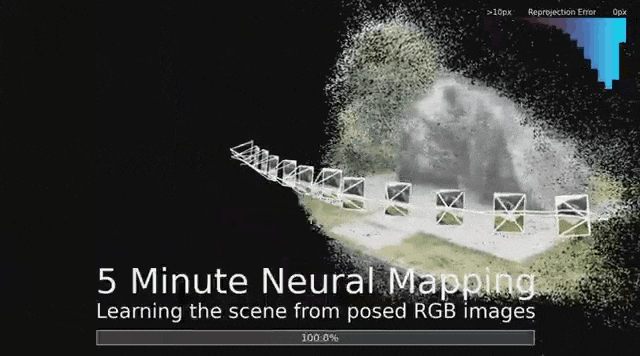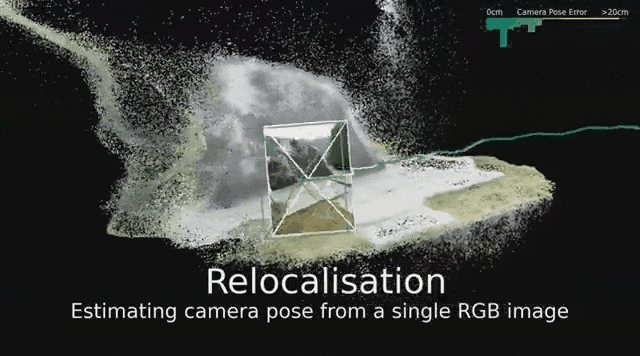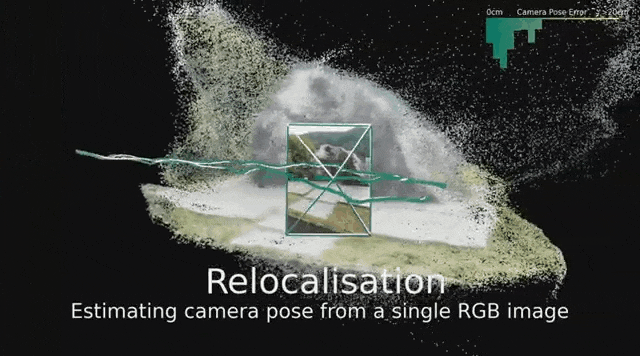
超越本地模型,让空间理解更宏大
而且,团队还有一个宏伟的愿景。
虽然当前的神经地图,已经是一个比较庞大的地理空间模型了,但他们想做的,是一个超越独立本地地图系统的更大规模的模型。
完全本地化的模型,可能无法完整覆盖各自的位置,无论在全球范围内有多少可用数据,局部上它们都是稀疏的。
局部模型的失败之处就在于,它无法超出已经看到的内容和位置进行推断。因此,本地模型只能定位与训练过的视图相似的相机视图。
现在 ,想象一下我们正站在一个教堂后面。
如果本地模型只见过教堂的前门,它是无法告诉你的准确位置的,因为它从未见过教堂的背面。
但是在全球范围内,我们却见过数以千计的教堂,它们都是由其他地方的本地模型捕获。虽然没有哪座教堂完全相同,但许多教堂有共同的特征。

LGM用的正是访问这些分布式知识的方法。
它可以提炼出全球大规模模型中的共同信息,在本地模型之间实现通信和数据共享。
它可以内化教堂的概念,并且进一步理解这些建筑是如何构造的。
即使对于某个特定位置只绘制了教堂入口的地图,LGM也能够根据之前见过的数千座教堂,对教堂的背面做出明智的猜测。

因此,即使是VPS从未见过的视点和角度,LGM也能在定位中实现前所未有的鲁棒性。
可以说,全球模型实现了对世界的集中理解,而且完全是源自地理空间和视觉数据。通过全球插值,它能进行局部推断。
让AI像人一样理解
上述过程,类似于人类感知和想象世界的方式。
对于人类来说,即使是从不同的角度,也能自然而然地识别出我们以前见过的东西。
想象在欧洲老城蜿蜒街道中漫步,你依然能轻而易举地找到返回的路。

这看似理所当然的能力,背后蕴含着惊人的复杂性。尤其是,对于机器视觉技术来说极其困难。
AI若想拥有类人的理解力,便需要了解一些自然法则:
世界由固体物质组成的物体构成,因此有正面和背面。外观会根据一天中的时间和季节而变化。
同时,这也需要相当多的文化知识:许多人造物体的形状遵循特定的对称规则或其他通用布局类型——通常取决于地理区域。
早期的计算机视觉研究试图解读其中的一些规则以便将其硬编码到手工制作的系统中。
但现在,科学家们意识到,我们所追求的这种高度理解实际上只能通过大规模机器学习来实现。
这正是LGM所追求的目标。
在Niantic联手牛津大学的最新研究论文MicKey中,首次看到了从数据中出现的令人印象深刻的相机定位能力。

论文地址:https://arxiv.org/pdf/2404.06337
MicKey是一个神经网络,能够在剧烈的视点变化下将两个相机视图相对定位。
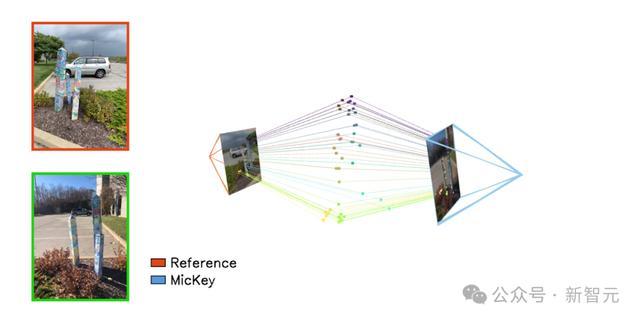
MicKey甚至可以处理需要人类花费一些努力才能弄清楚的对立镜头。
更令人兴奋的是,MicKey仅使用很少的训练数据,就取得了这样的成就。
MicKey限制于双视图输入,并在相对较少的数据上进行了训练,但它仍然是关于LGM潜力的概念验证。
显然,要实现高级空间智能,还需要海量的地理空间数据。
而Niantic的独特优势在于,每周都会收集超100万用户贡献的真实世界地点扫描。

多模型互补,重定义空间智能未来
LGM绝不仅仅是一个简单的定位模型。
为了很好地解决定位问题,LGM必须将丰富的几何、外观和文化信息编码到场景级特征中。这些特征将启用场景表示、操控和创造的新方式。
可以想象出,一个能够「理解」场景的智能系统,不仅能定位,还能感知周围环境深层次特征。
像LGM这样多功能大型AI模型,因其对多种下游应用的实用性,通常被称为「基础模型」。
未来的智能体系统,不再是孤立的存在,不同类型的基础模型将相互补充。
LLM将与多模态模型互动,而后者又与LGM进行通信。这些系统协同工作,以单一模型无法实现的方式理解世界。
这种互联是空间计算的未来——智能系统能够感知、理解并对物理世界采取行动。

随着迈向更具扩展性的模型,Niantic目标仍然是引领大规模地理空间模型的发展,创造前所未有的用户体验。
除了游戏,大规模地理空间模型将在空间规划与设计、物流、受众参与和远程协作等方面有广泛的应用。
LGM代表着AI进化的有一个里程碑。
随着AR眼镜等可穿戴设备变得更加普及,我们正迈向一个由物理和数字现实无缝融合的未来。